Embeddings for RAG with GO library
What are embeddings
Large Language Models store Data as embeddings. This is a usually an array of 1024 or 2048 vectors which points to a meaning. With that embedding, you can search for text with similar meaning. As there are many explanations about this, I do not want to go too deep.
An example:
- “Bad” is near to “Ungood”
- “Good” is near to “Excellent”
With that knowledge, you can search for text, which is similar to a given text. So if you want to build a FAQ (Frequently Asked Question) Database, you can search for the question which is most similar to the question you have.
With the older text search, if someone asks “In which blogpost did you write about apples?” you would have to search for “apples”.
With meaning, you would also find posts about fruits in general.
The technical architecture looks like this:
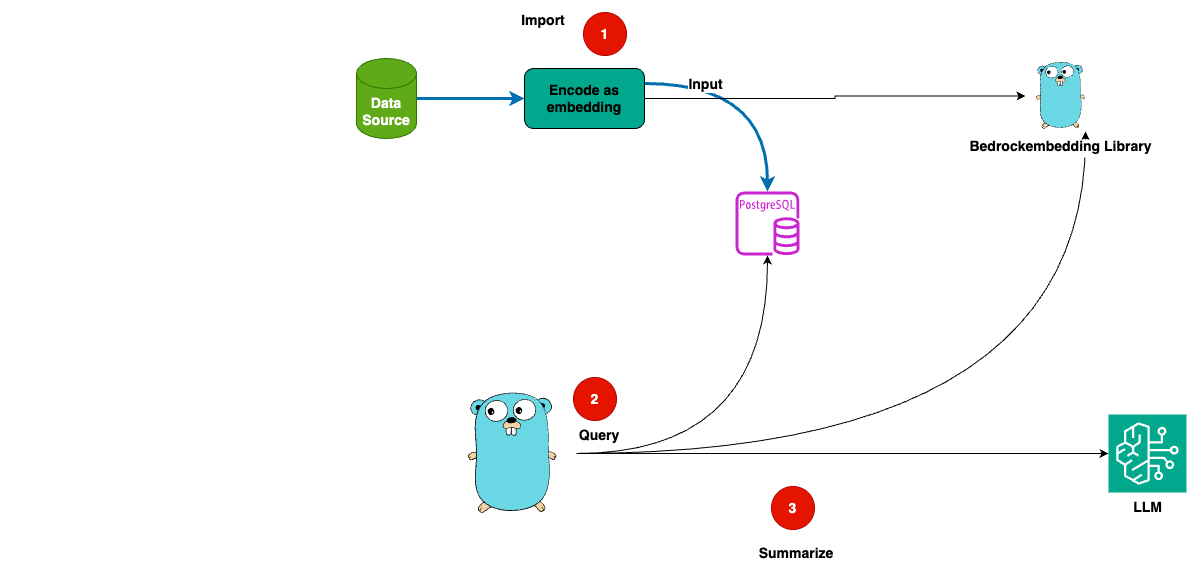
- You import the database with the embeddings vectors and the answers.
- For a given question, you calculate the embedding vector.
- Then you search in a vector database for the most similar vector.
You could show all results
Optionally, if you find more results, you could use a language model to summarize the results.
How to build embeddings
With this library, you can build embeddings for your text.
singleEmbedding, err := be.FetchEmbedding(content)
Lets look at titan/embeddings.go from Sources.
This will use Amazon Bedrock tian model to calculate the embedding for the text.
titanEmbeddingModelID = "amazon.titan-embed-text-v1" //https://docs.aws.amazon.com/bedrock/latest/userguide/model-ids-arns.html
...
output, err := Client.InvokeModel(context.Background(), &bedrockruntime.InvokeModelInput{
Body: payloadBytes,
ModelId: aws.String(titanEmbeddingModelID),
ContentType: aws.String("application/json"),
})
The response have embeddings and the token count:
type Response struct {
Embedding []float64 `json:"embedding"`
InputTextTokenCount int `json:"inputTextTokenCount"`
}
You unmarshal the response and get a Response struct.
var resp Response
err = json.Unmarshal(output.Body, &resp)
As Postgres uses []float32 we convert the response:
var embeddings []float32
for _, item := range resp.Embedding {
embeddings = append(embeddings, float32(item))
}
return embeddings, nil
As an example, how to use the library, see go-rag-pgvector-bedrock
We have this table in postgres:
| Name | Type |
|---|---|
| Content | text |
| Context | text |
| embedding | pgvector |
With a give question, we can do:
embedding, err := be.FetchEmbedding(question)
if err != nil {
...
}
rows, err := conn.Query(ctx, "SELECT id, content,context FROM documents ORDER BY embedding <=> $1 LIMIT 10", pgvector.NewVector(embedding))
With the operator <=> the semantic distance between the question and the content is calculated.
So you get all results ordered by similarity.
Source
See the full source on github.